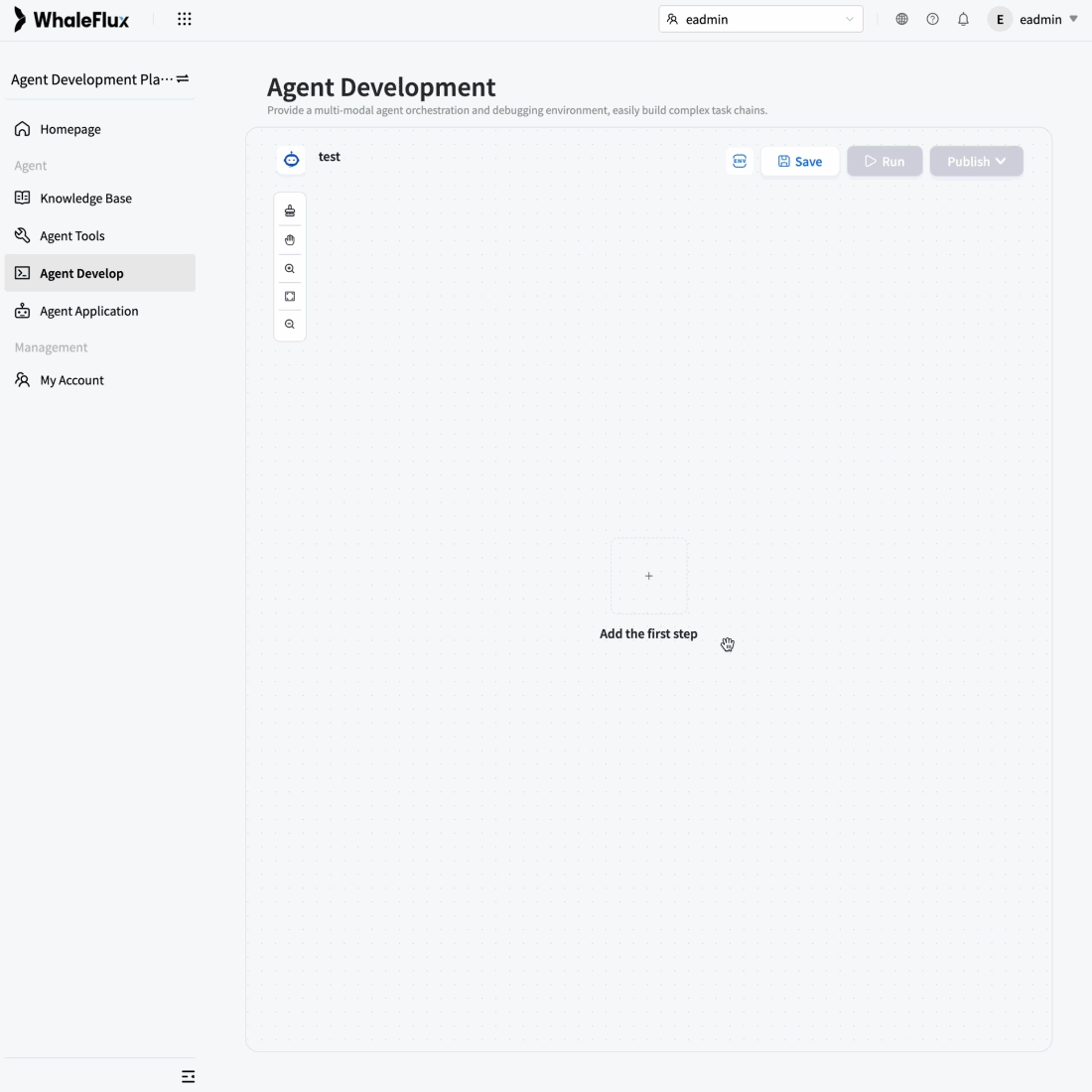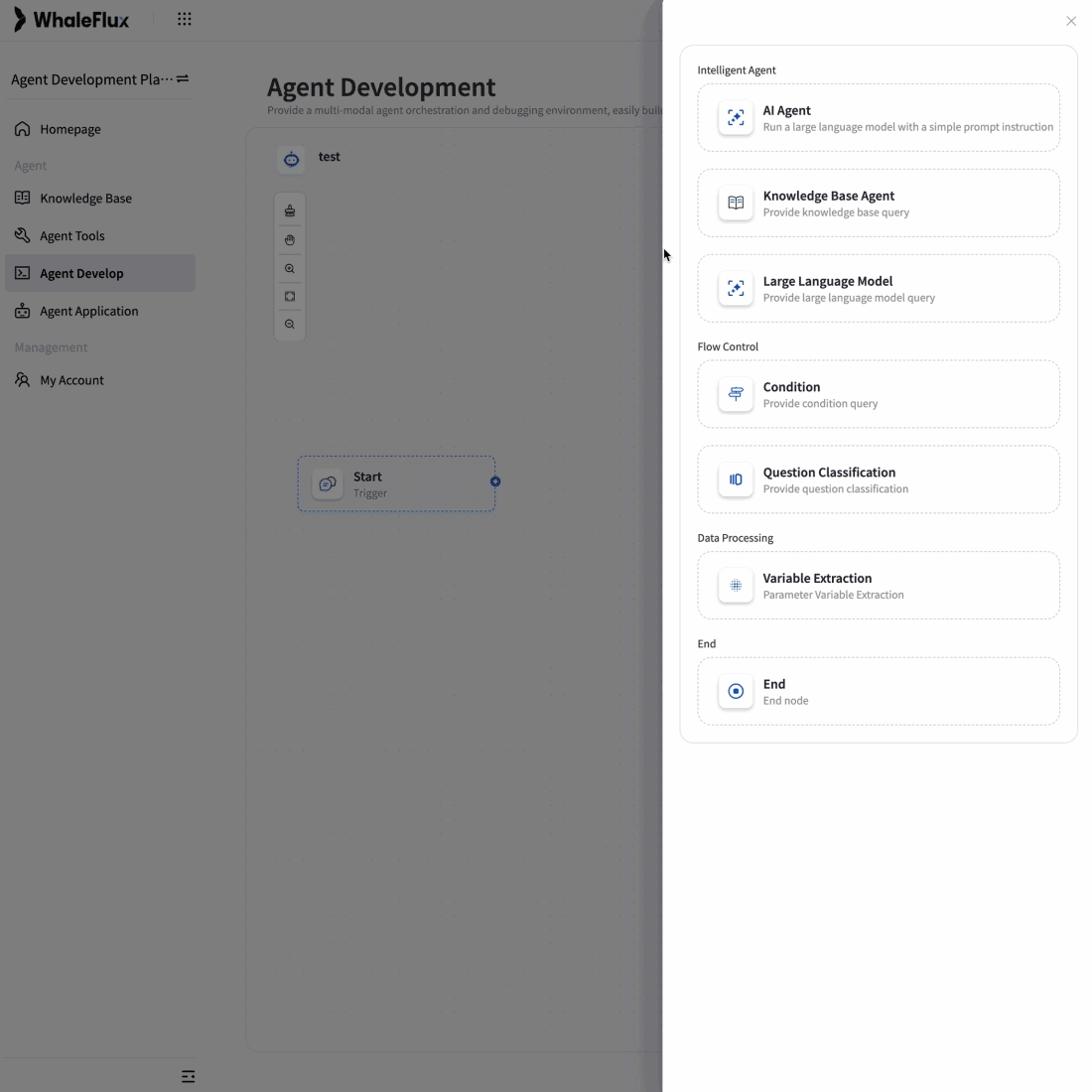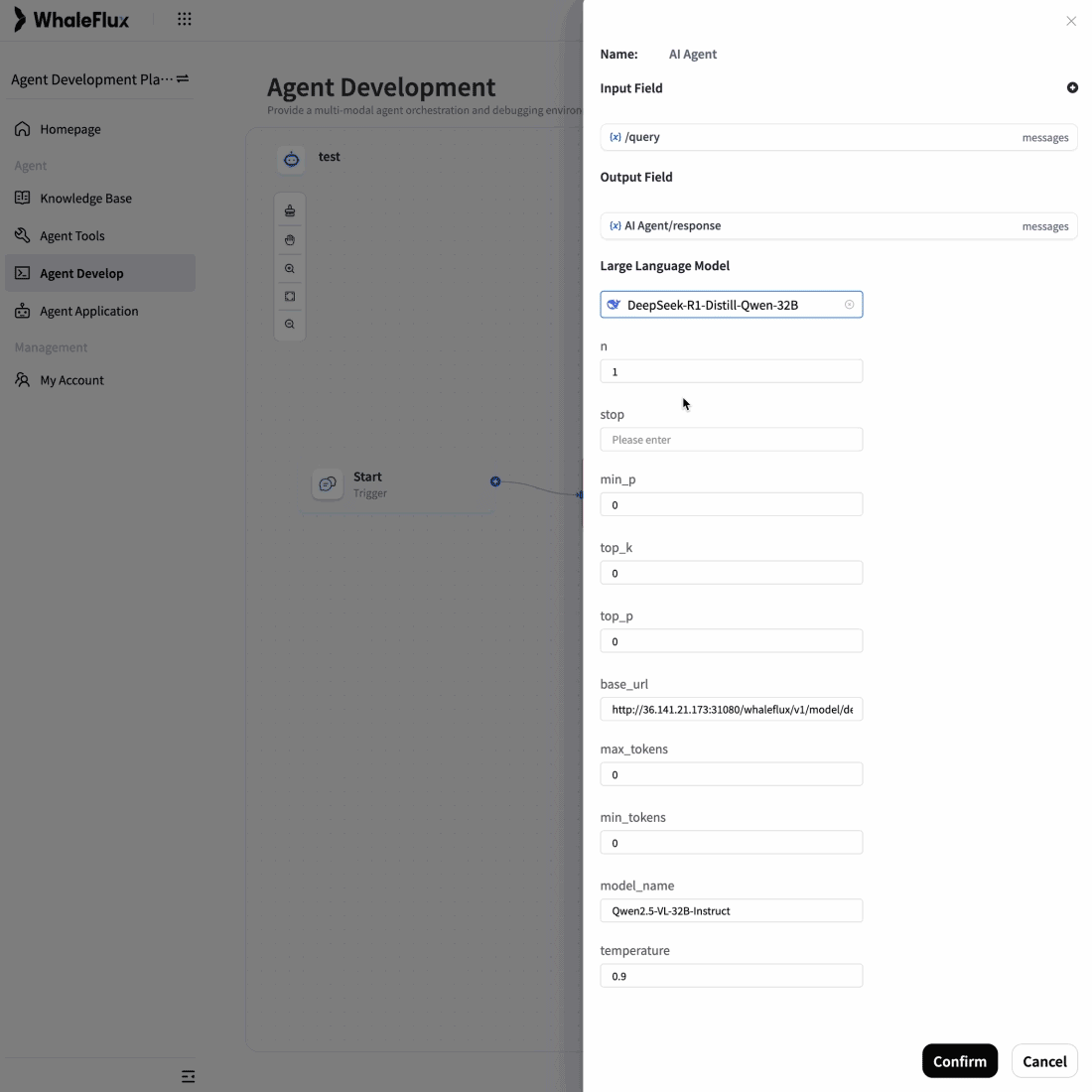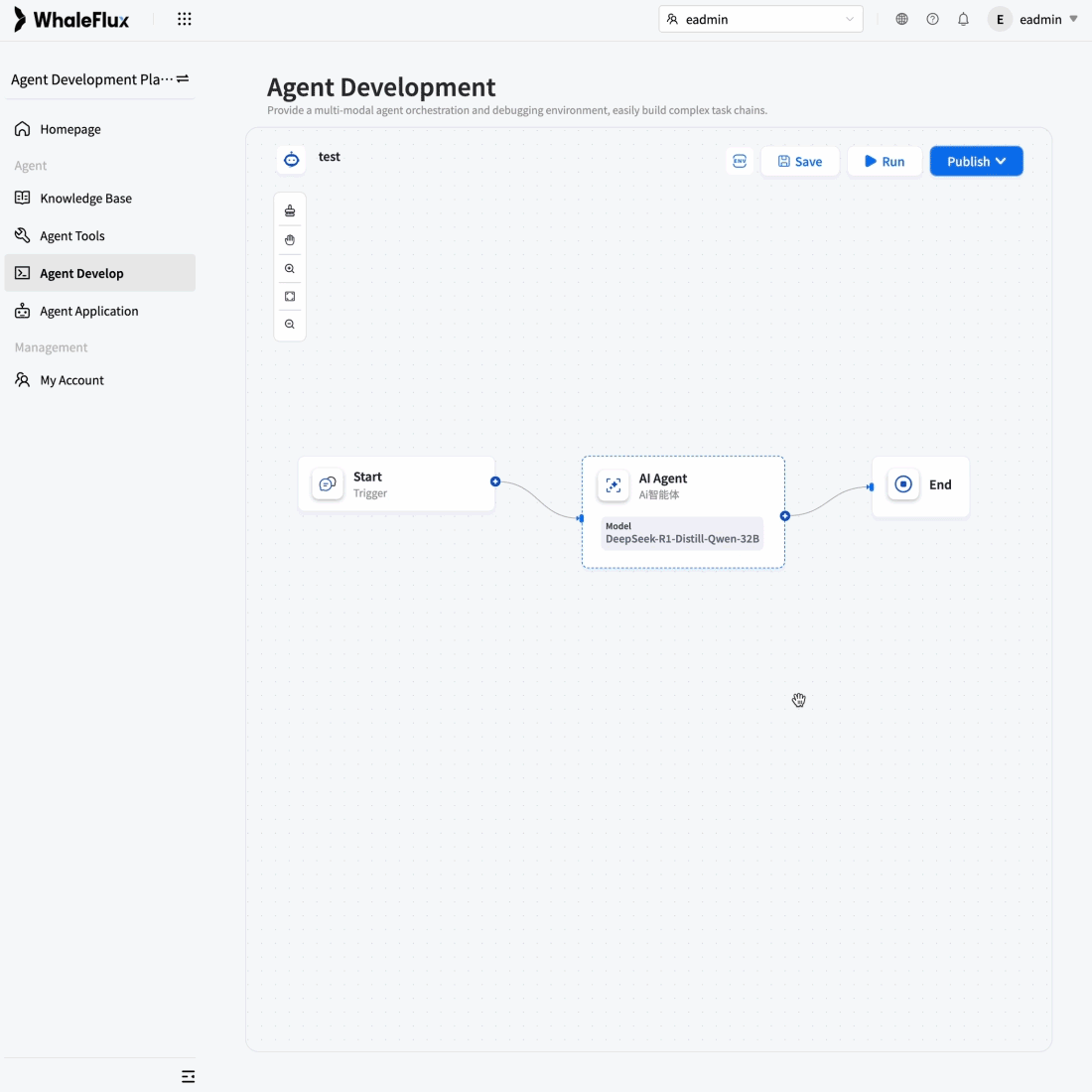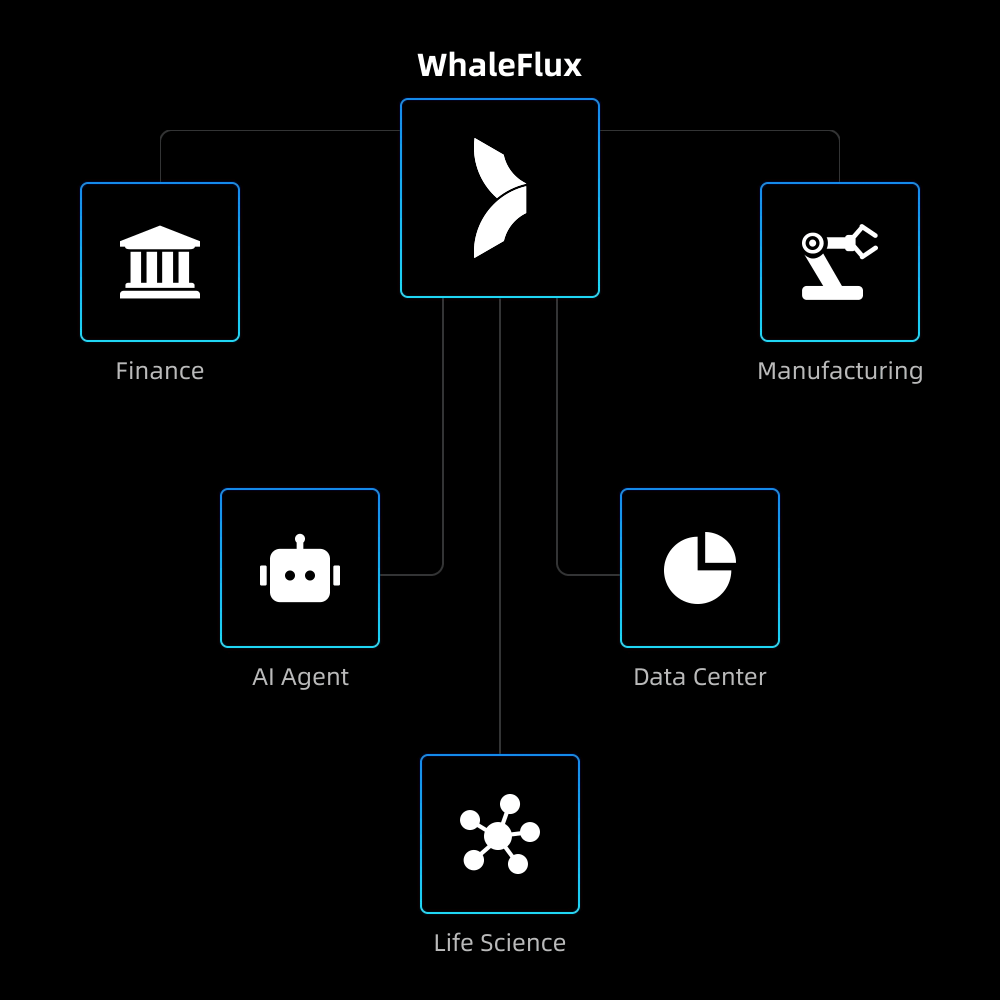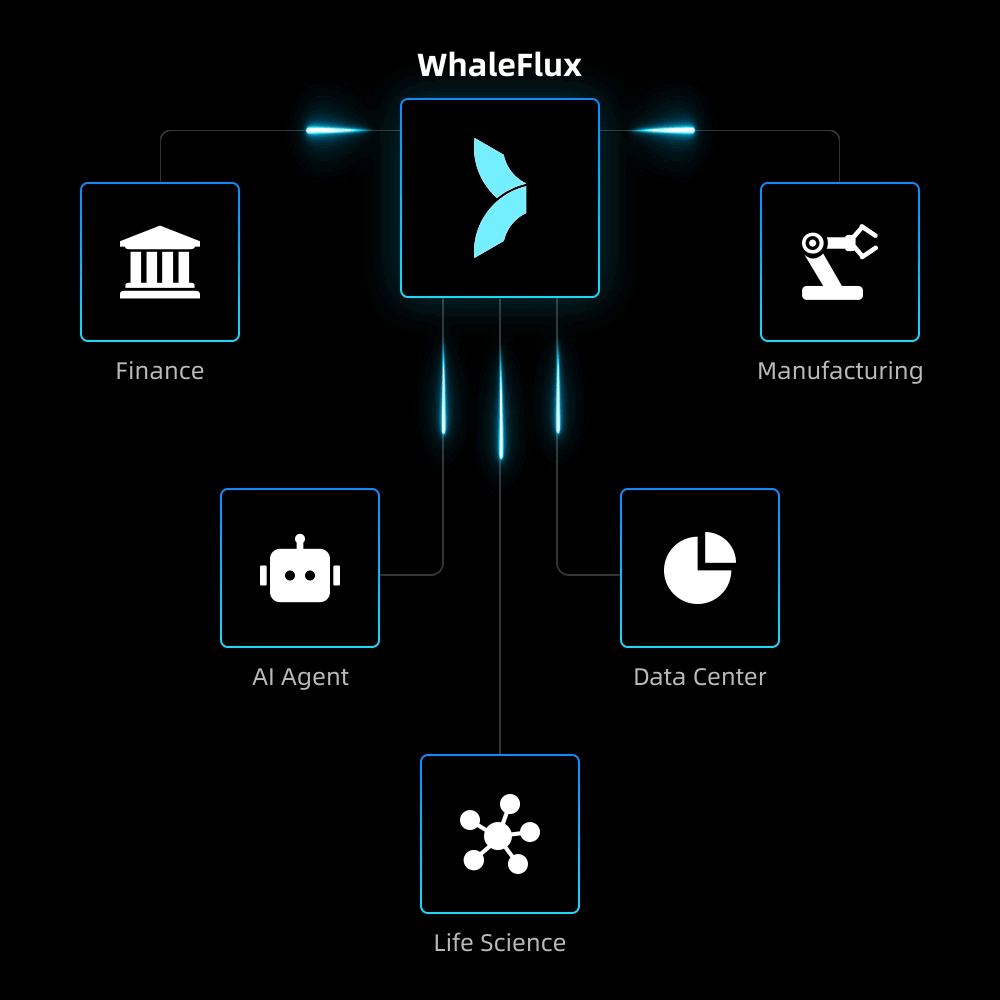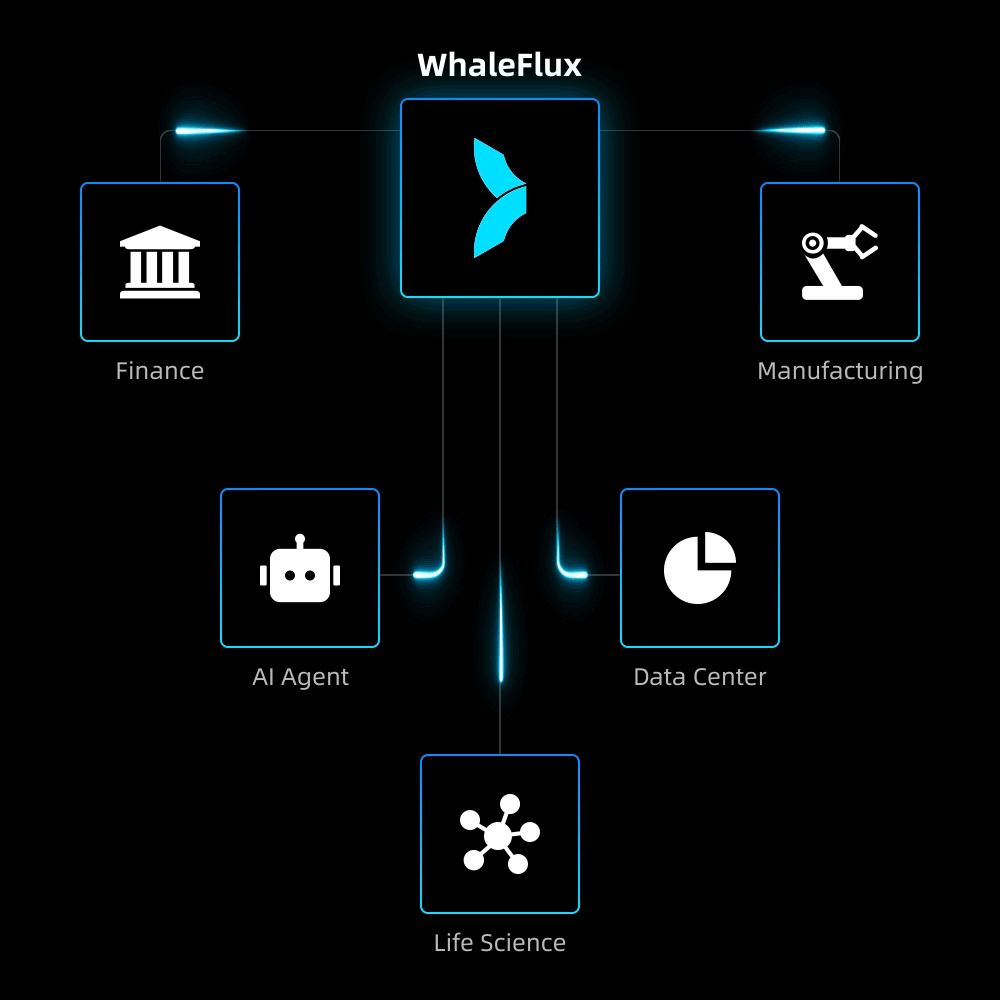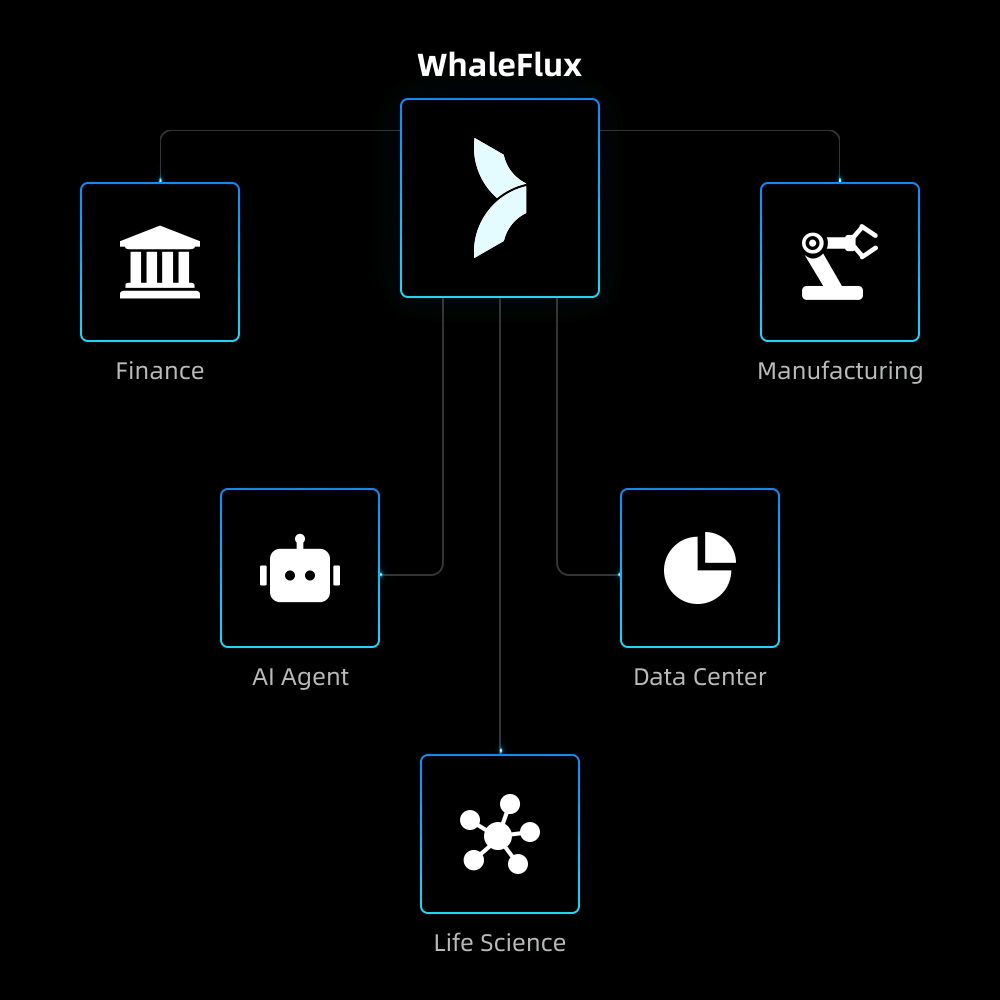






AI-Native Applications
Scaling an AI Application for 5× User Growth
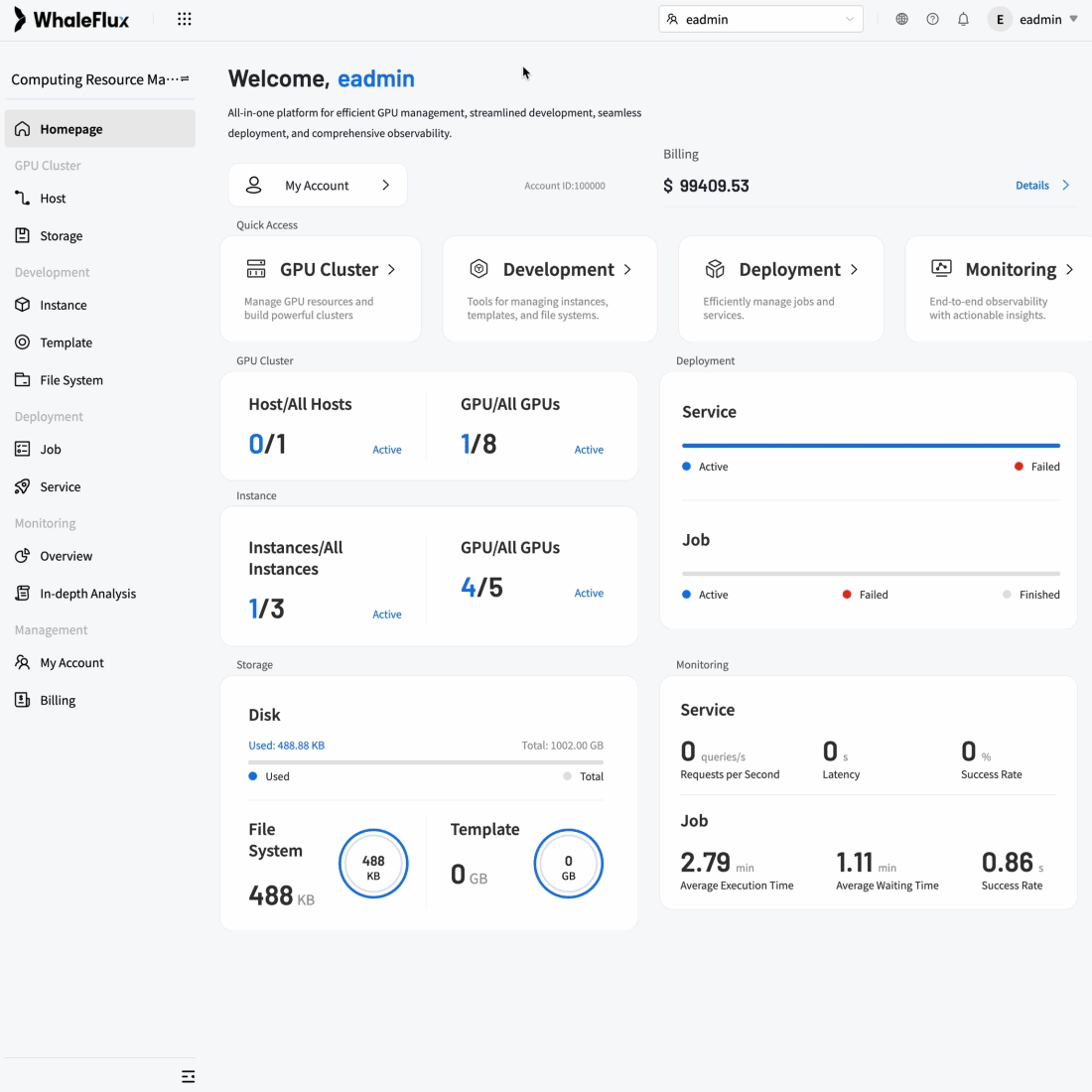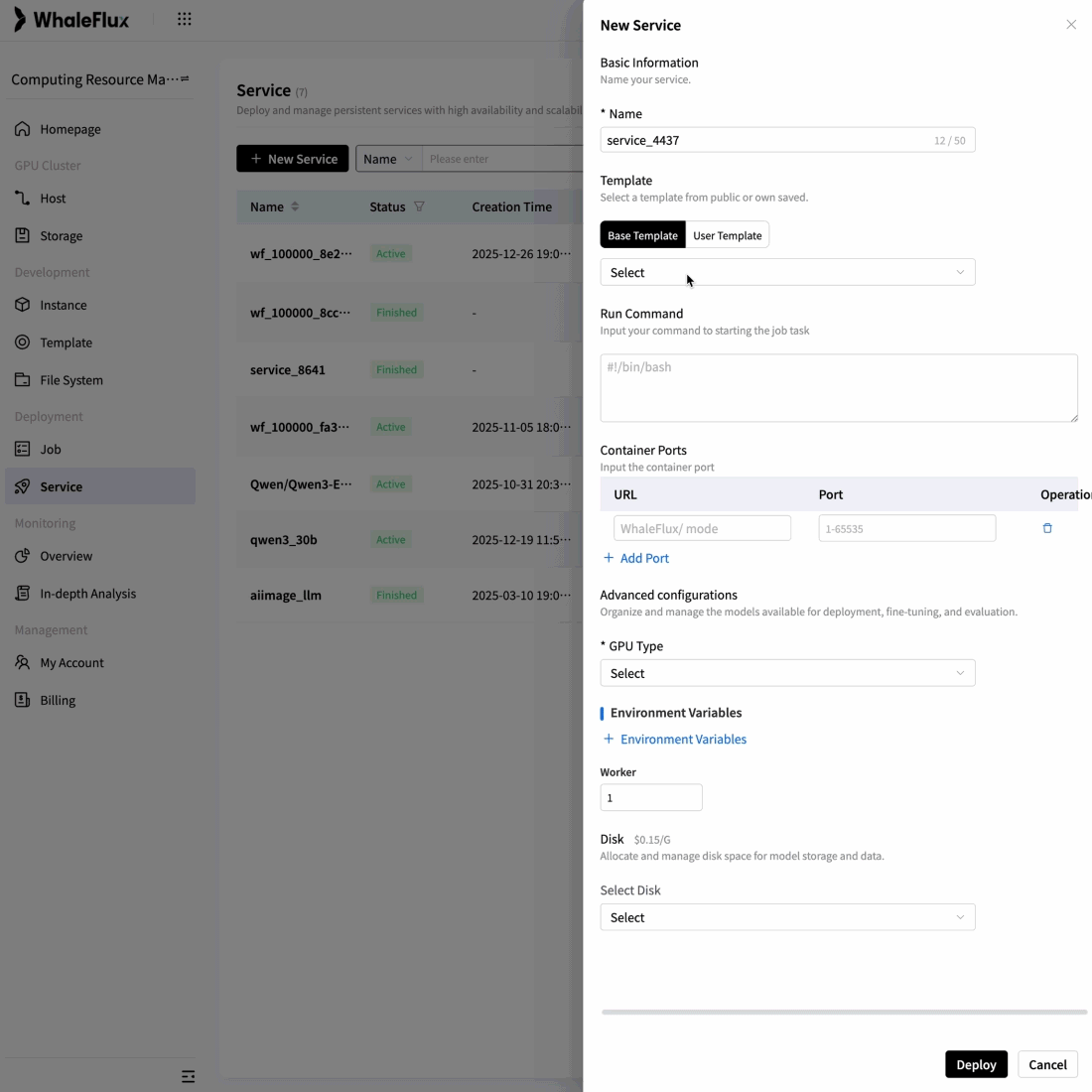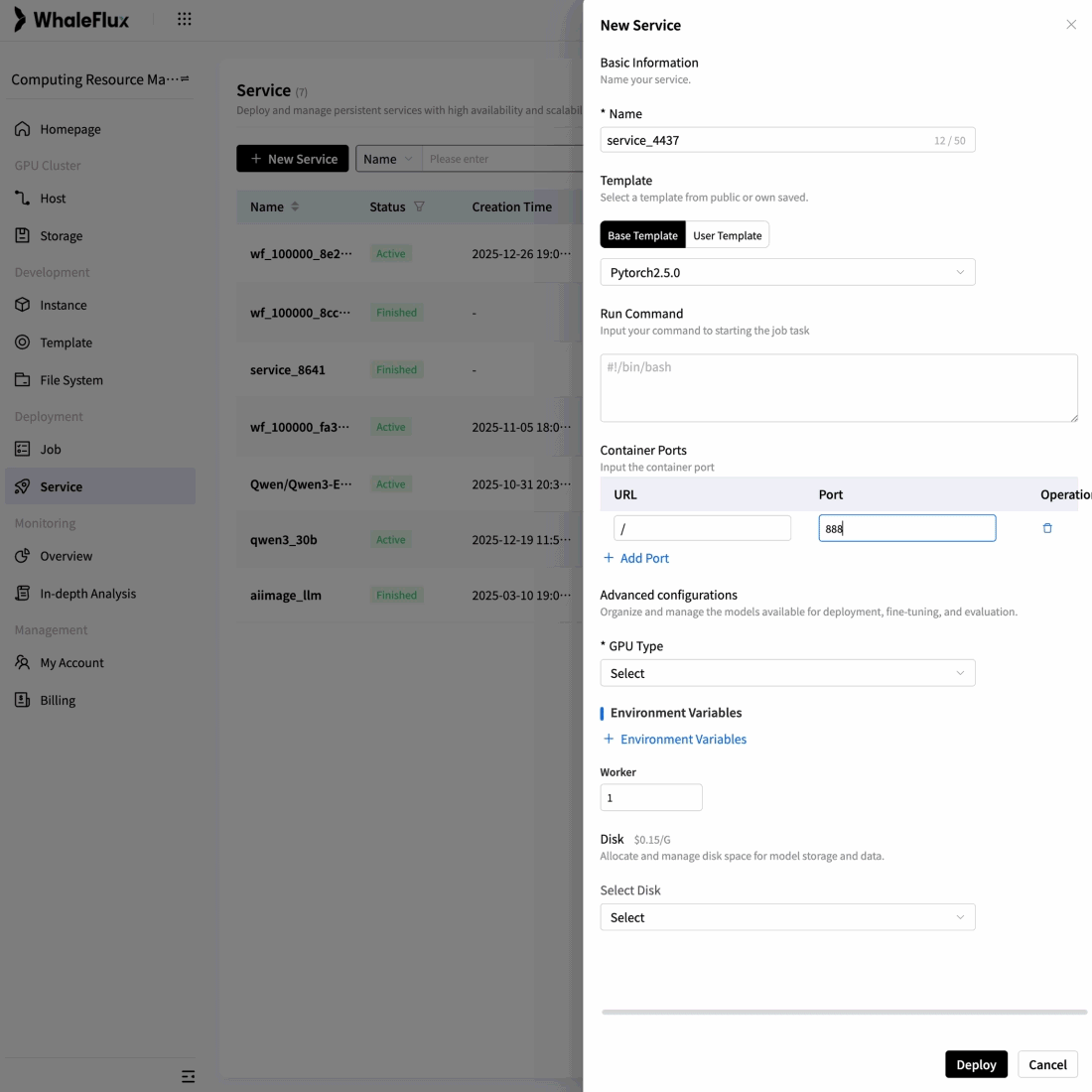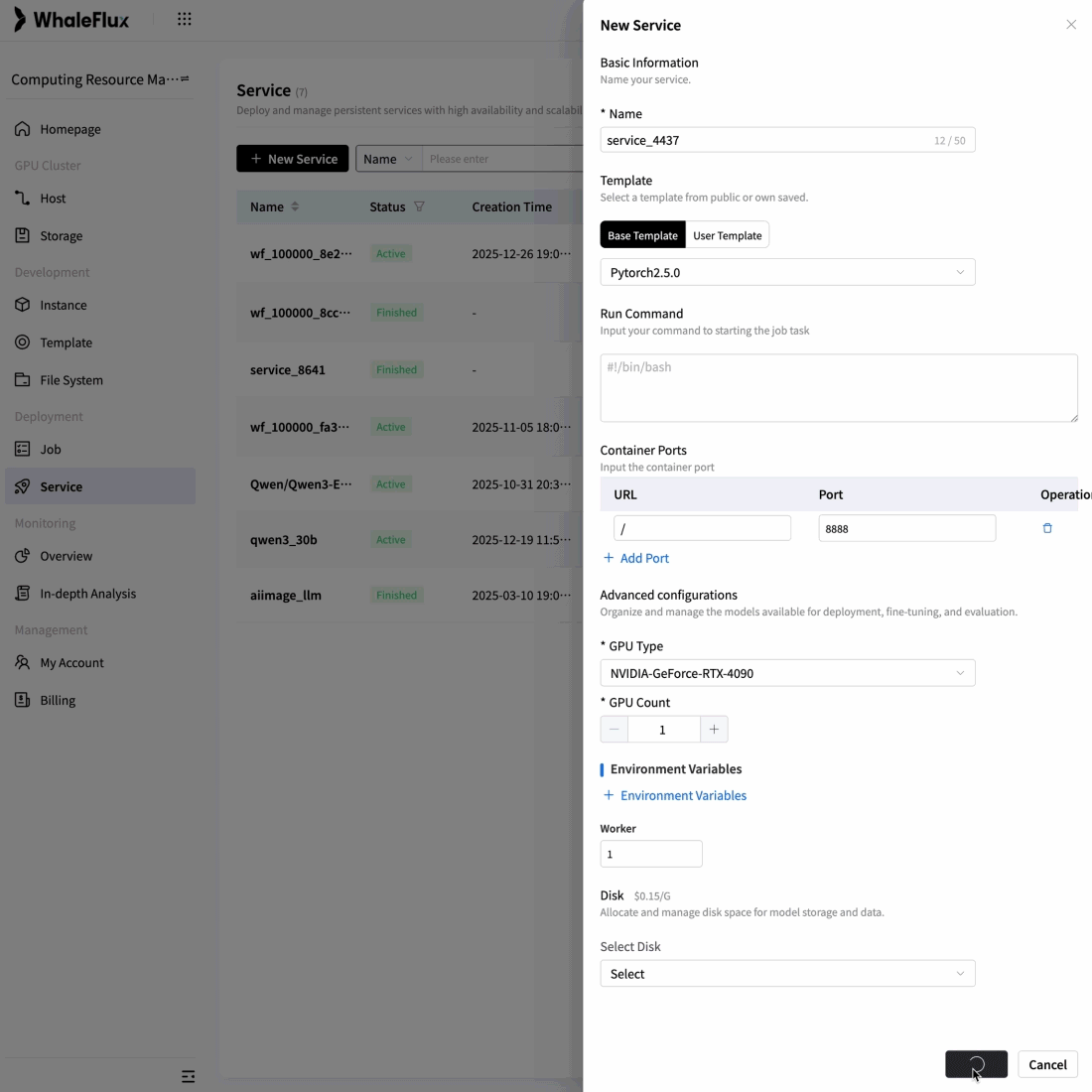
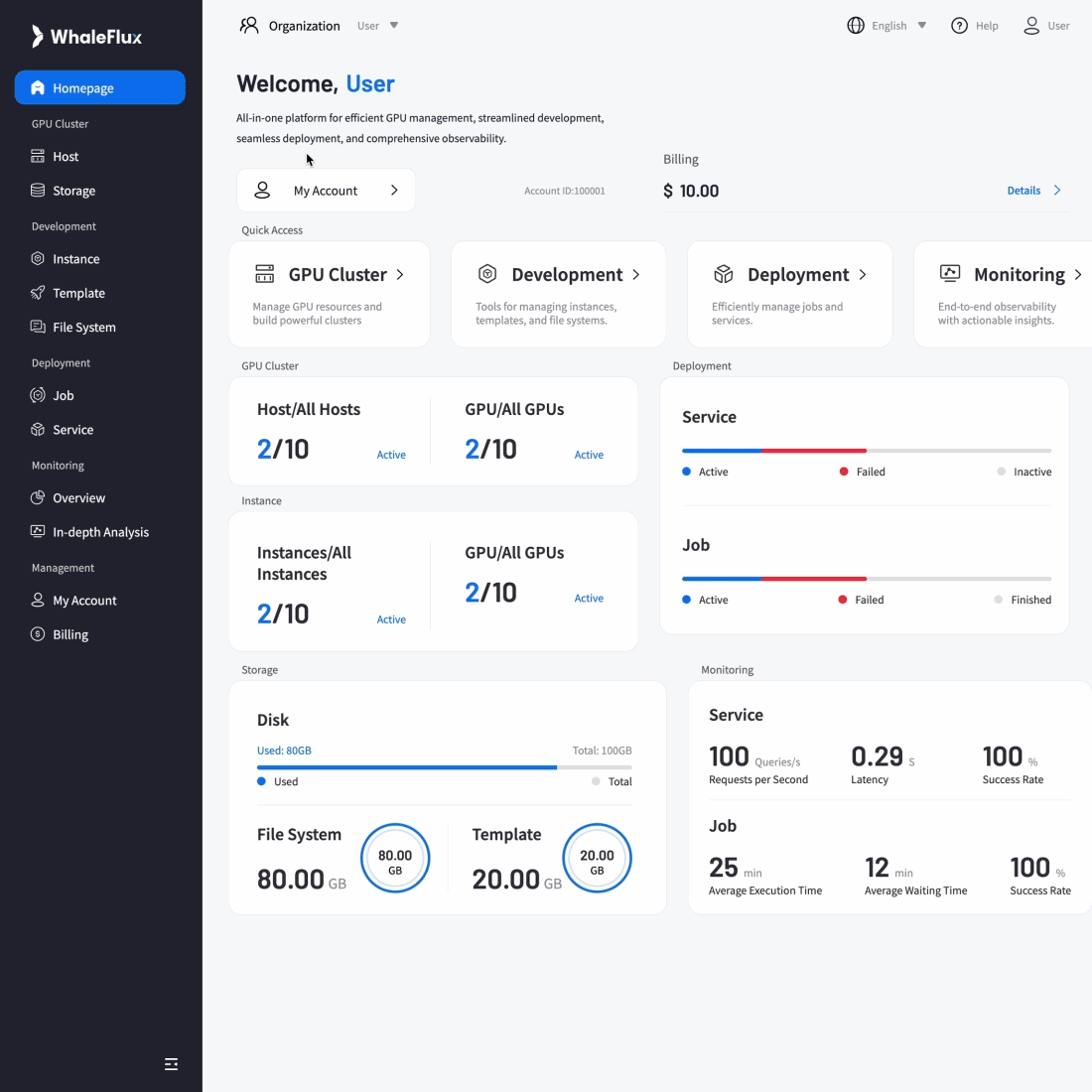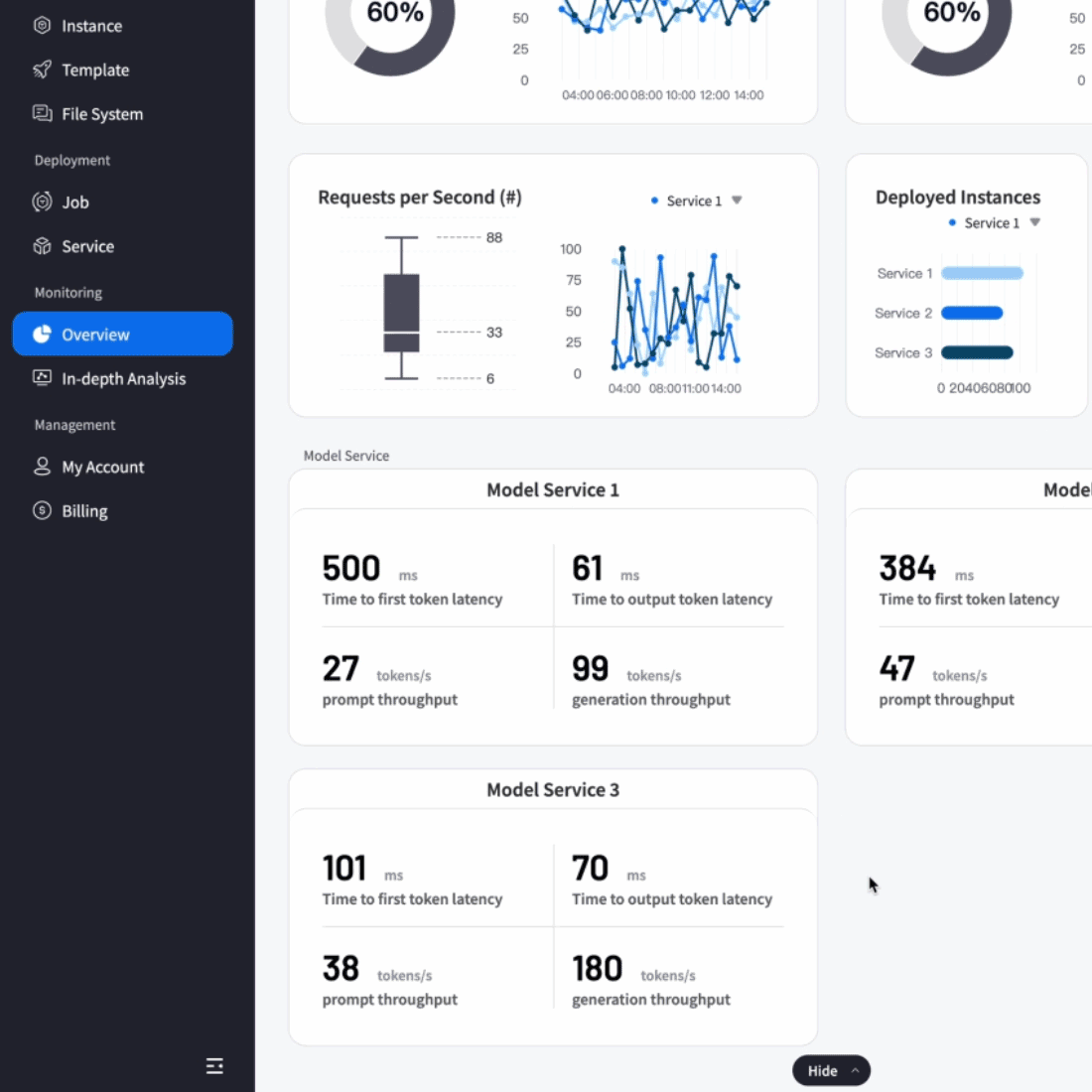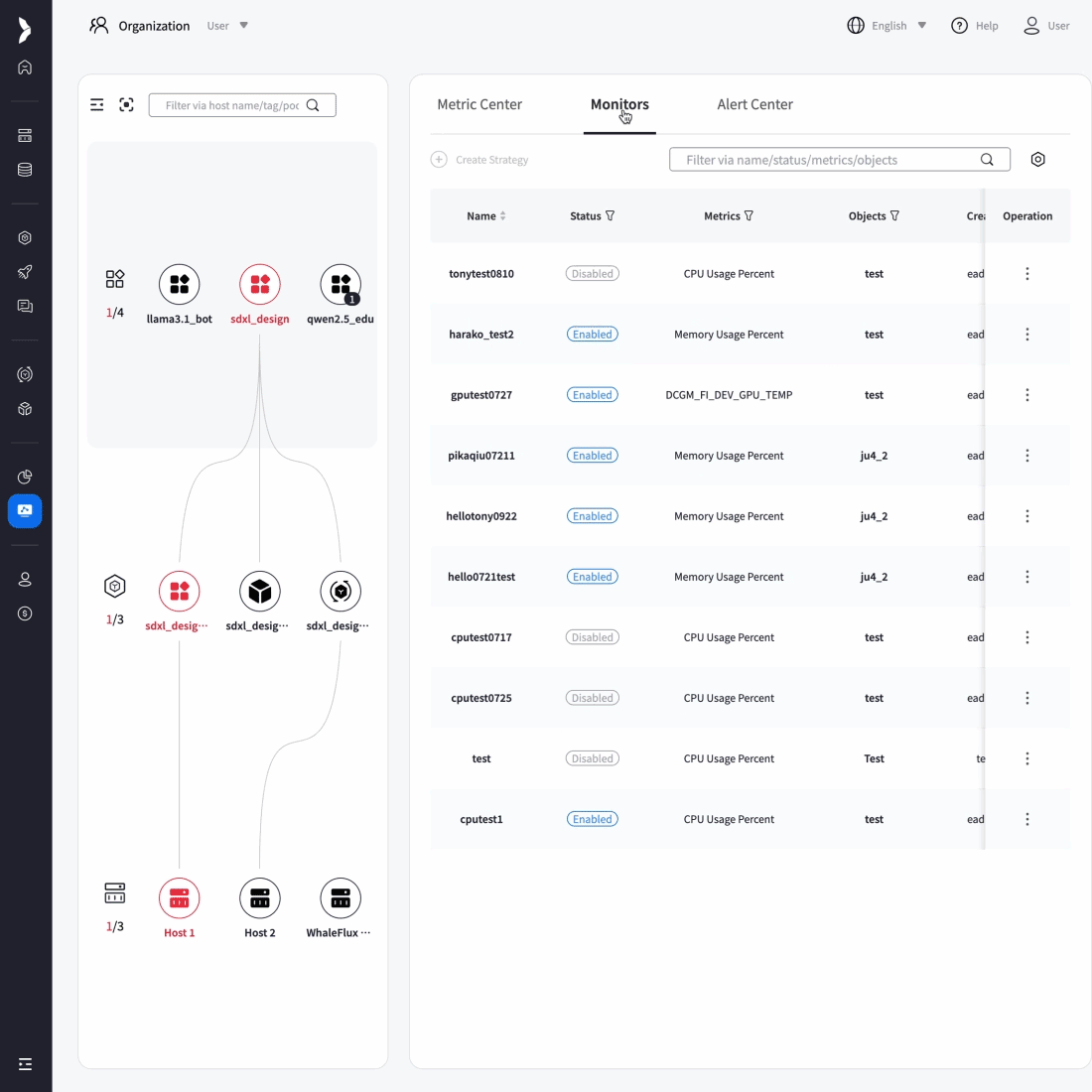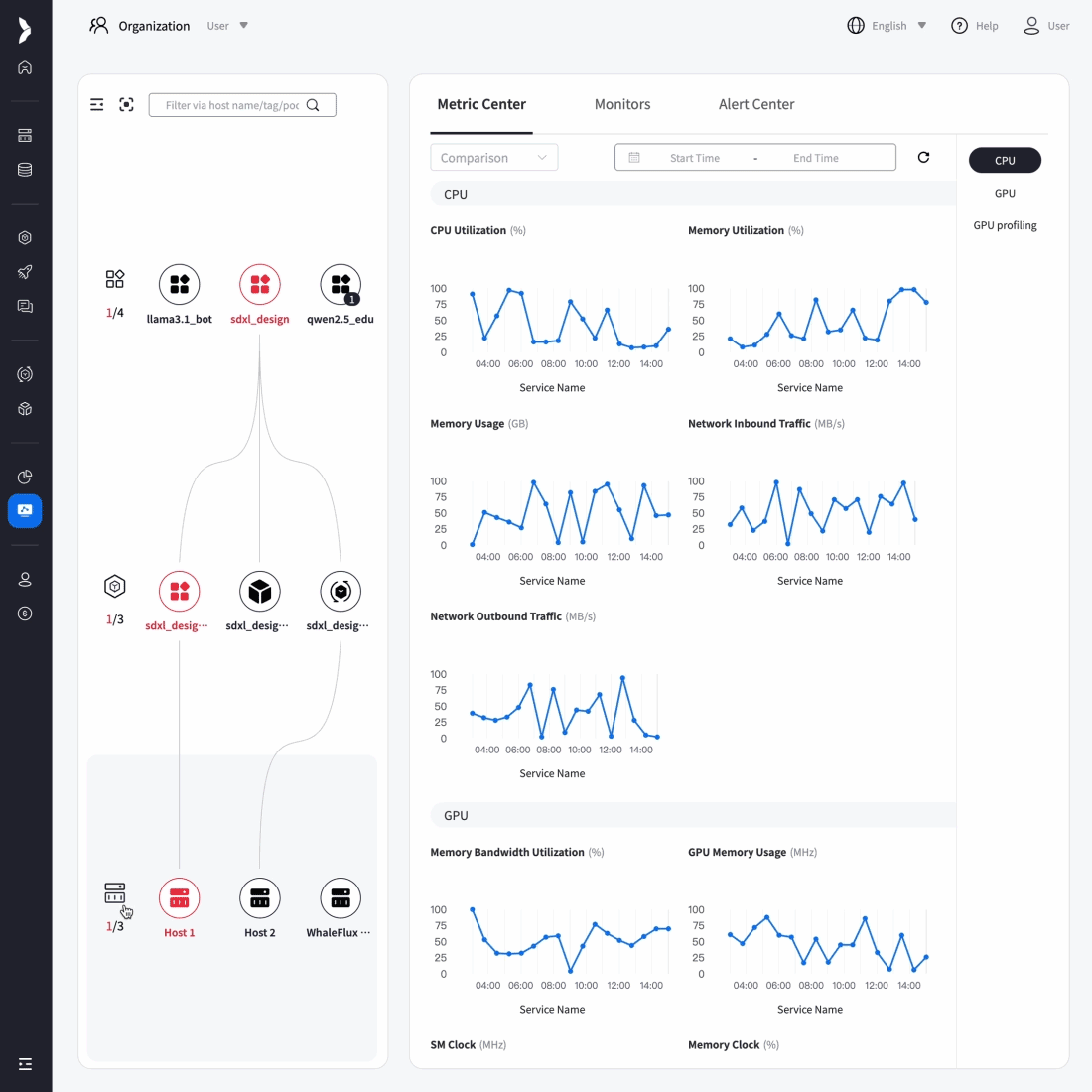
To overcome scalability bottlenecks and operational complexity, we delivered full-stack optimization and automated operations for their core AI application.
Result:5× increase in concurrent processing capacity, 90% reduction in failures, and seamless support for rapid user growth while maintaining reliability.