WhaleFlux
Delivers the infrastructure for performant, scalable, and cost-efficient
deployment and
serving of AI models.
WhaleFlux Provides Optimal
Performance for Your AI Workload

How WhaleFlux Supports
Your AI Model Services
Intelligent Compute Resource Management
WhaleFlux delivers high-performance GPUs with proprietary testing, fine-grained resource management, and flexible configurations for stable, efficient operation—whether for single GPUs or clusters, short- or long-term.
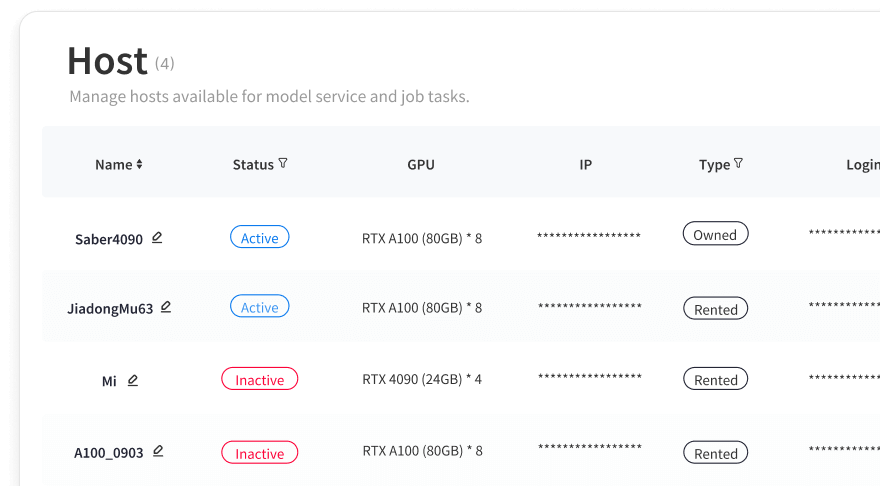
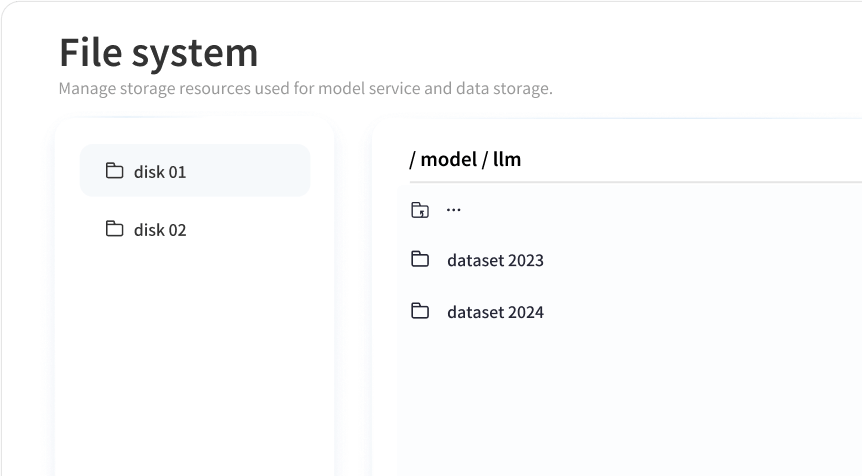
Model Development Center
Simplify the development process with WhaleFlux’s seamless workflows. Users can quickly create template-based environments without complex configurations and manage images and file systems with ease.
Smart Deployment & Scheduling
WhaleFlux enables quick deployment and smart scheduling for AI models, optimizing performance with automated strategy adjustments for seamless operations and fine-tuning.
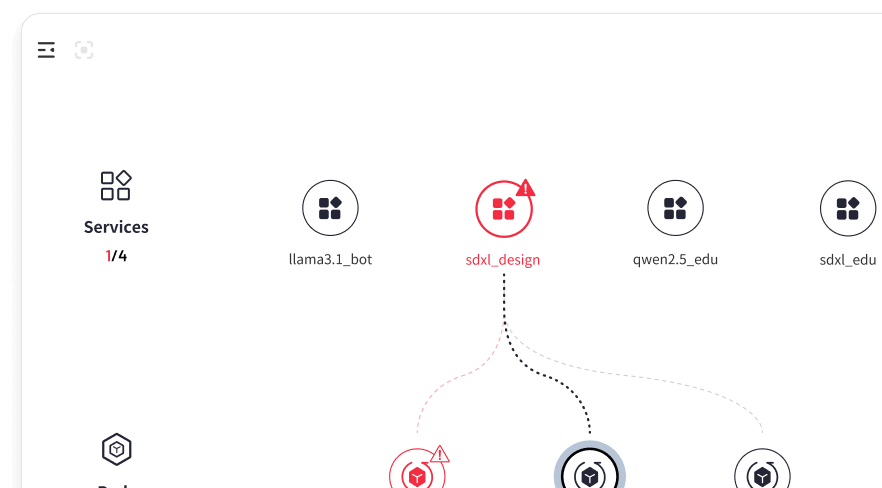
Full-Stack Performance Monitoring
Gain a comprehensive view of resources and service operations with WhaleFlux’s global topology. Monitor 30+ multidimensional metrics covering hardware performance, service health, and gateway execution, ensuring real-time visibility across all levels.
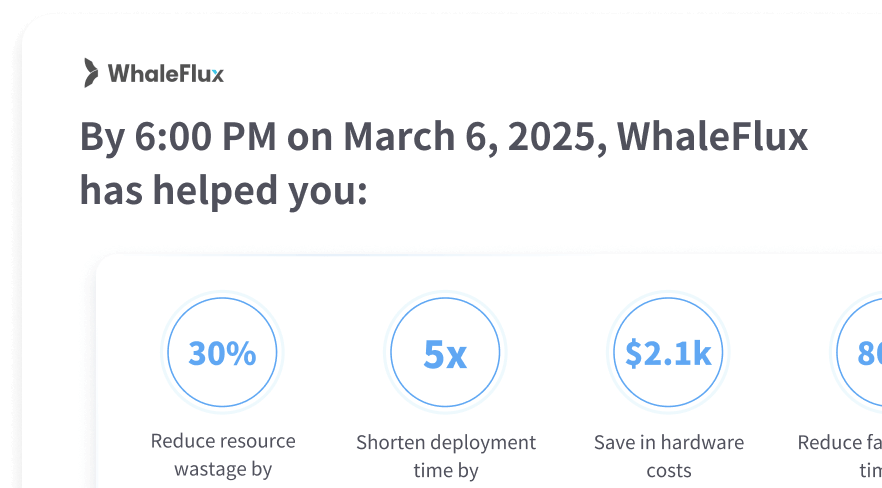
Powering AI Model Services with
WhaleFlux’s Cutting-Edge Technologies
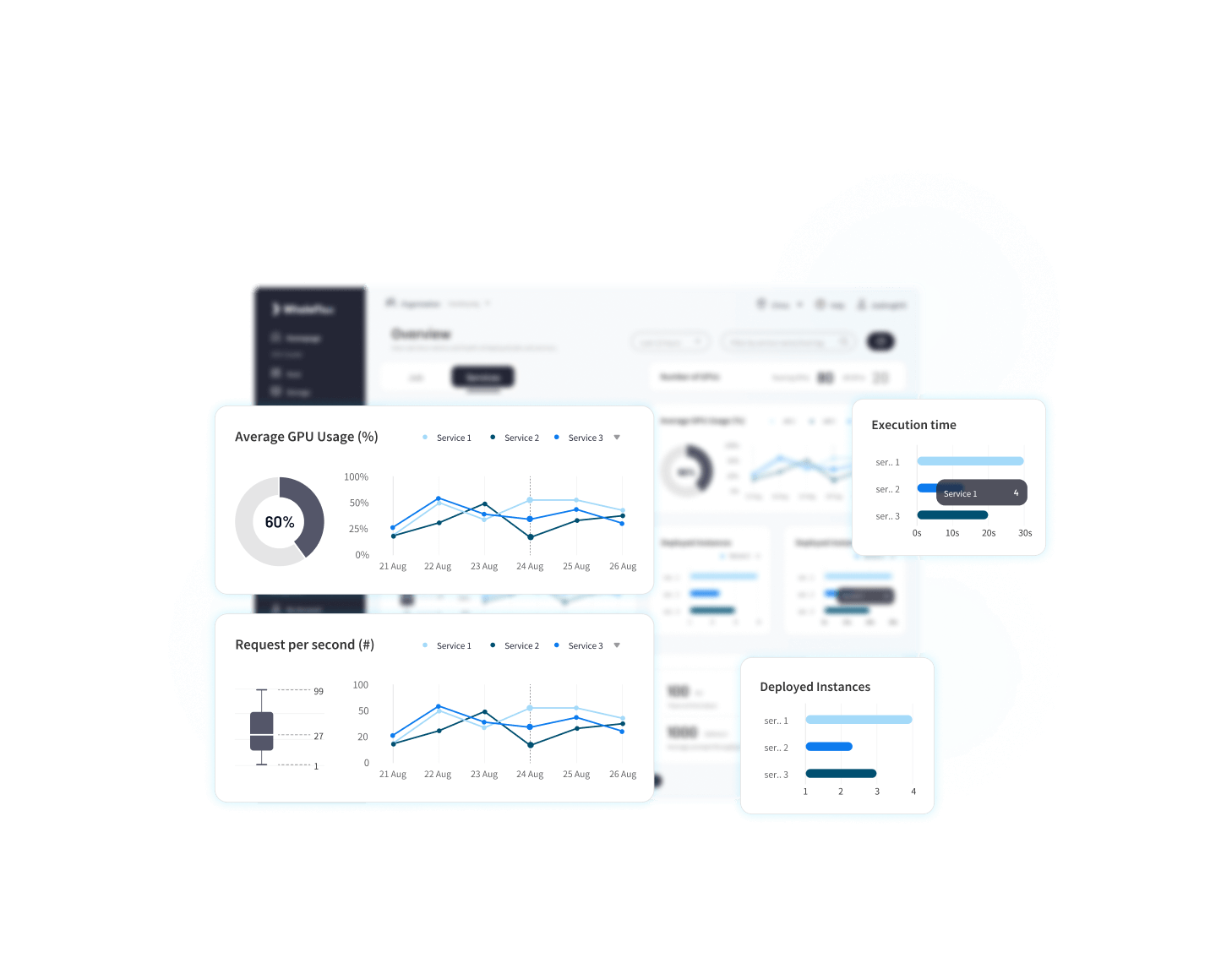
01 Thread-level Observability
Pinpoints performance bottlenecks by offering deep insights into the full stack of AI model application.
Deliver comprehensive thread-level visibility across GPU clusters, LLMs, and applications
30+ proprietary observability key metrics
An AI-powered system for monitoring, alerts, self-healing, and optimization to predict and swiftly resolve potential risks
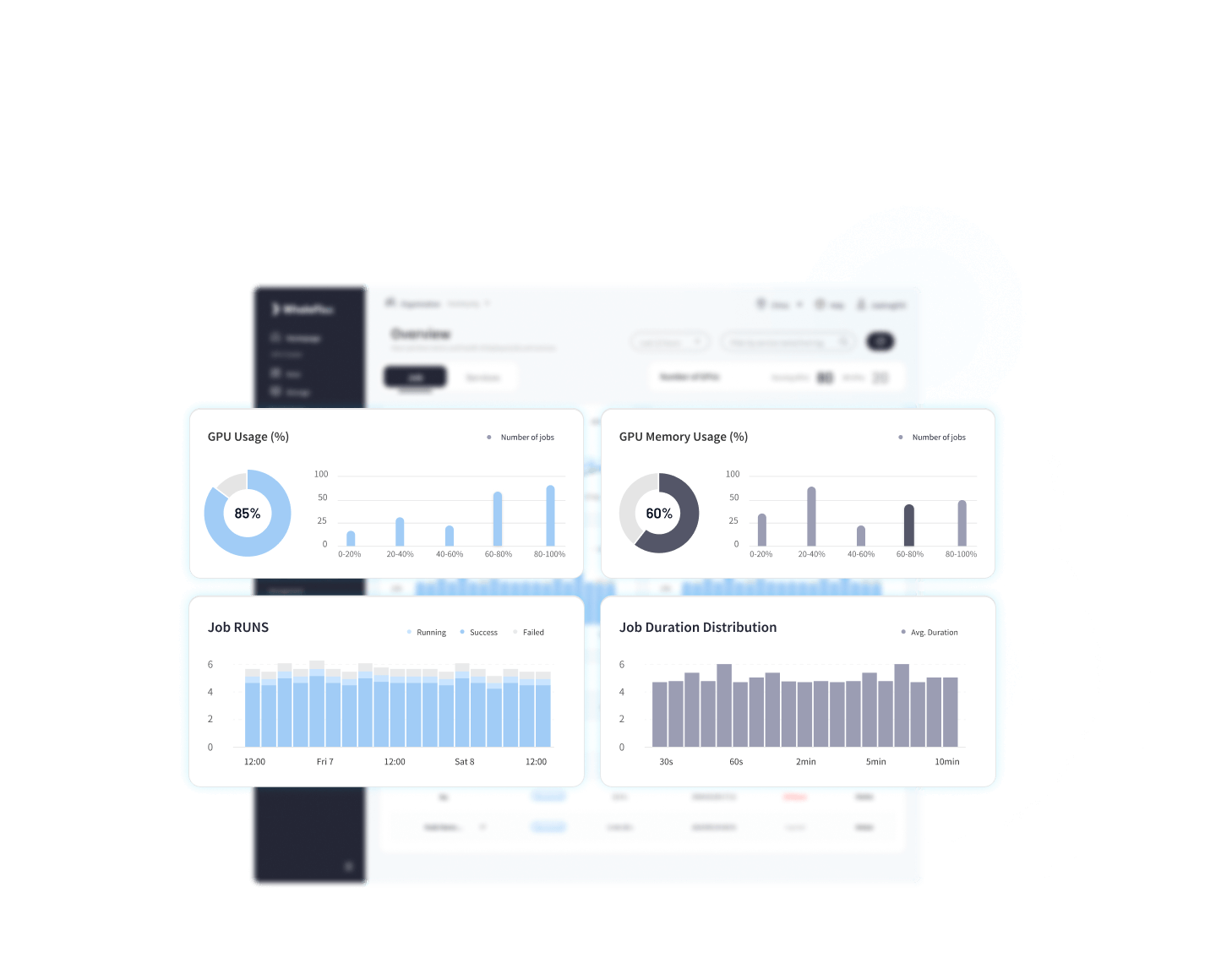
02
Workload/GPU Profiling
& Affinity Analysis
Optimize AI Performance with Intelligent Resource Allocation
Workload Profiling: Analyze compute intensity, memory usage, and GPU capabilities
Dynamic Matching: Align workloads with optimal GPUs for efficiency
Task Optimization: Assign tasks based on GPU performance and memory needs
Data Locality: Reduce transfer by placing tasks near data sources
Resource Isolation: Dedicate GPUs to critical tasks, avoiding contention
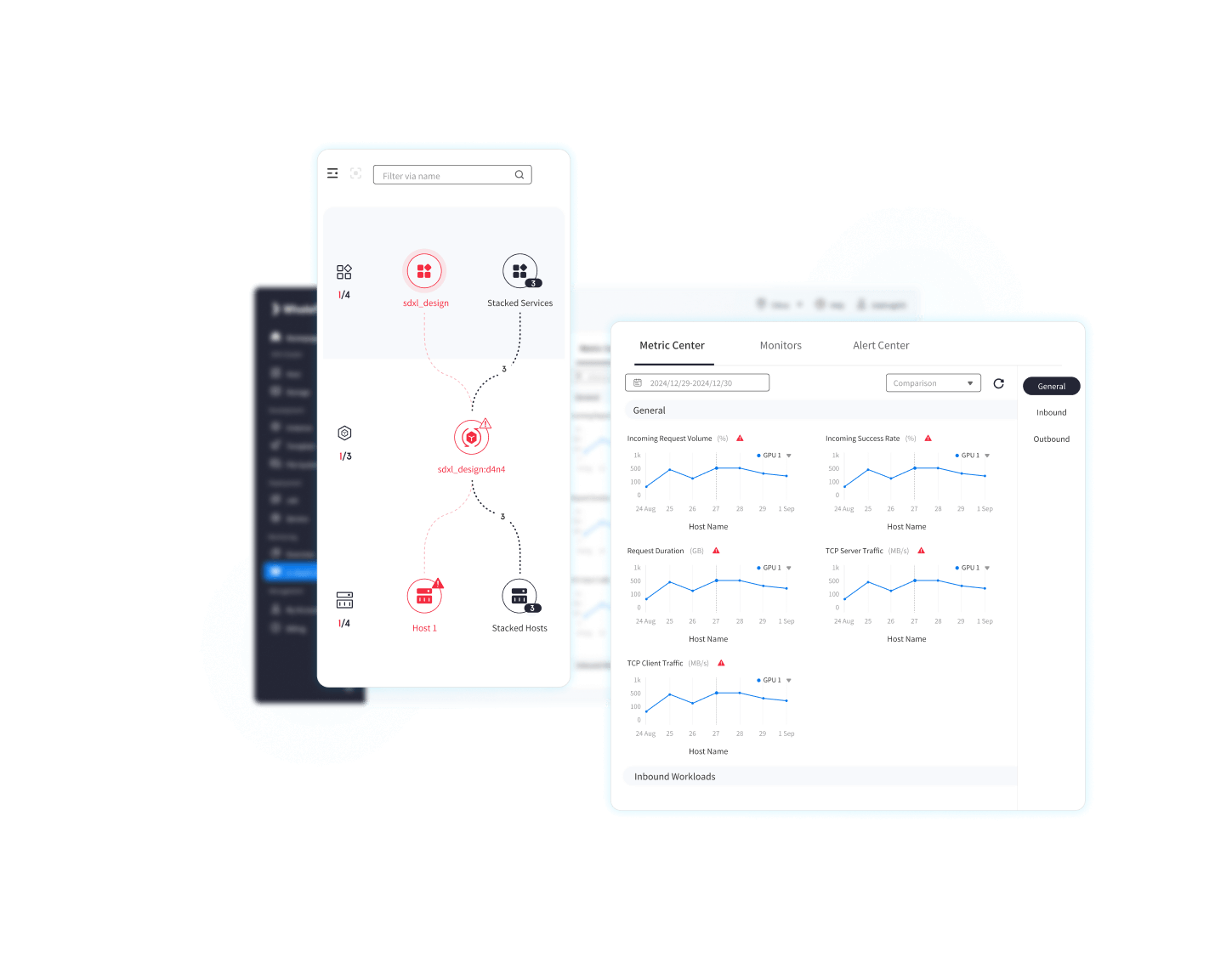
03 Atomic-level Scheduling
Optimize the utilization of computational resources for peak performance
Meticulous management of computing resources
Real-time resource scheduling for high-concurrency request scenarios
Optimal resource scheduling to minimize electricity power costs